
Logistic Regression is a commonly used machine learning algorithm for binary classification problems, where the goal is to predict one of two possible outcomes. However, in some cases, the target variable has more than two classes. In such cases, a multiclass classification problem is encountered. In this article, we will see how to create a logistic regression model using the scikit-learn library for multiclass classification problems.
Multinomial classification
Multinomial logistic regression is used when the dependent variable in question is nominal (equivalently categorical, meaning that it falls into any one of a set of categories that cannot be ordered in any meaningful way) and for which there are more than two categories. Some examples would be:
- Which major will a college student choose, given their grades, stated likes and dislikes, etc.?
- Which blood type does a person have, given the results of various diagnostic tests?
- In a hands-free mobile phone dialing application, which person’s name was spoken, given various properties of the speech signal?
- Which candidate will a person vote for, given particular demographic characteristics?
- Which country will a firm locate an office in, given the characteristics of the firm and of the various candidate countries?
These are all statistical classification problems. They all have in common a dependent variable to be predicted that comes from one of a limited set of items that cannot be meaningfully ordered, as well as a set of independent variables (also known as features, explanators, etc.), which are used to predict the dependent variable. Multinomial logistic regression is a particular solution to classification problems that use a linear combination of the observed features and some problem-specific parameters to estimate the probability of each particular value of the dependent variable. The best values of the parameters for a given problem are usually determined from some training data (e.g. some people for whom both the diagnostic test results and blood types are known, or some examples of known words being spoken).
Common Approaches
- One-vs-Rest (OvR)
- Softmax Regression (Multinomial Logistic Regression)
- One vs One(OvO)
Multiclass classification problems are usually tackled in two ways – One-vs-Rest (OvR), One-vs-One (OvO) and using the softmax function. In the OvA / OvR approach, a separate binary classifier is trained for each class, where one class is considered positive and all other classes are considered negative. In the OvO approach, a separate binary classifier is trained for each pair of classes. For example, if there are k classes, then k(k-1)/2 classifiers will be trained in the OvO approach.
In this article, we will be using the OvR and softmax approach to create a logistic regression model for multiclass classification.
One-vs-Rest (OvR)
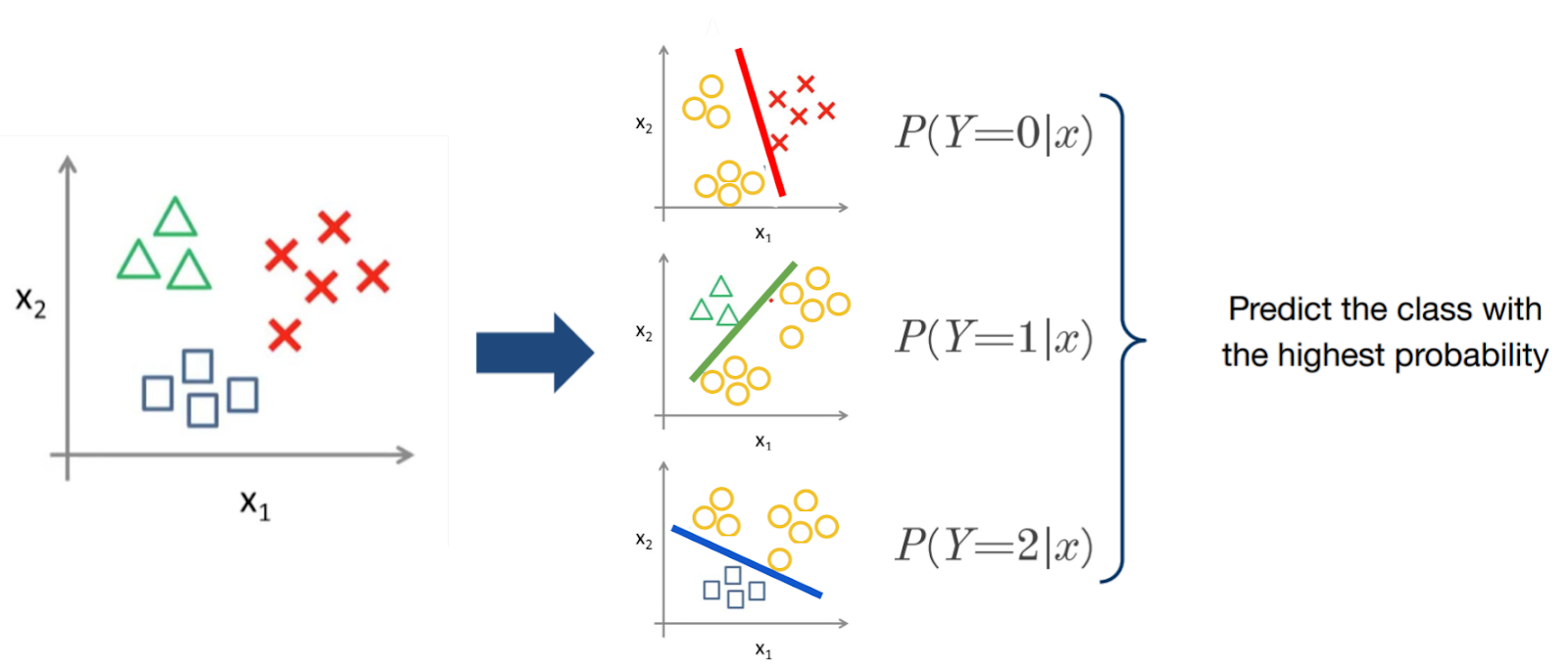
One-vs-rest (OvR for short, also referred to as One-vs-All or OvA) is a heuristic method for using binary classification algorithms for multi-class classification.
It involves splitting the multi-class dataset into multiple binary classification problems. A binary classifier is then trained on each binary classification problem and predictions are made using the model that is the most confident.
For example, given a multi-class classification problem with examples for each class ‘red,’ ‘blue,’ and ‘green‘. This could be divided into three binary classification datasets as follows:
- Binary Classification Problem 1: red vs [blue, green]
- Binary Classification Problem 2: blue vs [red, green]
- Binary Classification Problem 3: green vs [red, blue]
A possible downside of this approach is that it requires one model to be created for each class. For example, three classes require three models. This could be an issue for large datasets (e.g. millions of rows), slow models (e.g. neural networks), or very large numbers of classes (e.g. hundreds of classes).
This approach requires that each model predicts a class membership probability or a probability-like score. The argmax of these scores (class index with the largest score) is then used to predict a class.
As such, the implementation of these algorithms in the scikit-learn library implements the OvR strategy by default when using these algorithms for multi-class classification.
The strategy for handling multi-class classification can be set via the “multi_class” argument and can be set to “ovr” for the one-vs-rest strategy when using sklearn’s LogisticRegression class from linear_model.
To start, we need to import the required libraries:
import numpy as np import pandas as pd from sklearn.datasets import load_iris from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split
Next, we will load the load_iris dataset from the sklearn.datasets library, which is a commonly used dataset for multiclass classification problems:
iris = load_iris() X = iris.data y = iris.target
The load_iris dataset contains information about the sepal length, sepal width, petal length, and petal width of 150 iris flowers. The target variable is the species of the iris flower, which has three classes – 0, 1, and 2.
Next, we will split the data into training and testing sets. 80%-20% split:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
Training the multiclass logistic regression model
Now, we can create a logistic regression model and train it on the training data:
model = LogisticRegression(solver='lbfgs', multi_class='ovr') model.fit(X_train, y_train)
The multi_class parameter is set to ‘ovr’ to indicate that we are using the OvA approach for multiclass classification. The solver parameter is set to ‘lbfgs’ which is a suitable solver for small datasets like the load_iris dataset.
Next, we can evaluate the performance of the model on the test data:
y_pred = model.predict(X_test)
accuracy = np.mean(y_pred == y_test)
print("Accuracy:", accuracy)The predict method is used to make predictions on the test data, and the accuracy of the predictions is calculated by comparing the predicted values with the actual values.
Finally, we can use the trained model to make predictions on new data:
new_data = np.array([[5.1, 3.5, 1.4, 0.2]])
y_pred = model.predict(new_data)
print("Prediction:", y_pred)In this example, we have taken a single new data point with sepal length 5.1, sepal width 3.5, petal length 1.4, and petal width 0.2. The model will return the predicted class for this data point.
Become a Data Analyst with Experience

Become a Machine Learning Engineer with Experience
-
 Machine Learning Engineer Work Experience Certification Course ProgramProduct on sale₹69,999
Machine Learning Engineer Work Experience Certification Course ProgramProduct on sale₹69,999

Softmax Regression (Multinomial Logistic Regression)
The inputs to the multinomial logistic regression are the features we have in the dataset. Suppose if we are going to predict the Iris flower species type, the features will be the flower sepal length, width and petal length and width parameters will be our features. These features will be treated as the inputs for the multinomial logistic regression.
The keynote to remember here is the features values are always numerical. If the features are not numerical, we need to convert them into numerical values using the proper categorical data analysis techniques.
Linear Model
The linear model equation is the same as the linear equation in the linear regression model. You can see this linear equation in the image. Where the X is the set of inputs, Suppose from the image we can say X is a matrix. Which contains all the feature( numerical values) X = [x1,x2,x3]. Where W is another matrix includes the same input number of coefficients W = [w1,w2,w3].
In this example, the linear model output will be the w1x1, w2x2, w3*x3
Softmax Function
The softmax function is a mathematical function that takes a vector of real numbers as input and outputs a probability distribution over the classes. It is often used in machine learning for multiclass classification problems, including neural networks and logistic regression models.
The softmax function is defined as:

The softmax function transforms the input vector into a probability distribution over the classes, where each class is assigned a probability between 0 and 1, and the sum of the probabilities is 1. The class with the highest probability is then selected as the predicted class.
The softmax function is a generalization of the logistic function used in binary classification. In binary classification, the logistic function is used to output a single probability value between 0 and 1, representing the probability of the input belonging to the positive class.
The softmax function is different from the sigmoid function, which is another function used in machine learning for binary classification. The sigmoid function outputs a value between 0 and 1, which can be interpreted as the probability of the input belonging to the positive class.
Cross Entropy
The cross-entropy is the last stage of multinomial logistic regression. Uses the cross-entropy function to find the similarity distance between the probabilities calculated from the softmax function and the target one-hot-encoding matrix.
Cross-entropy is a distance calculation function which takes the calculated probabilities from softmax function and the created one-hot-encoding matrix to calculate the distance. For the right target class, the distance value will be smaller, and the distance values will be larger for the wrong target class.
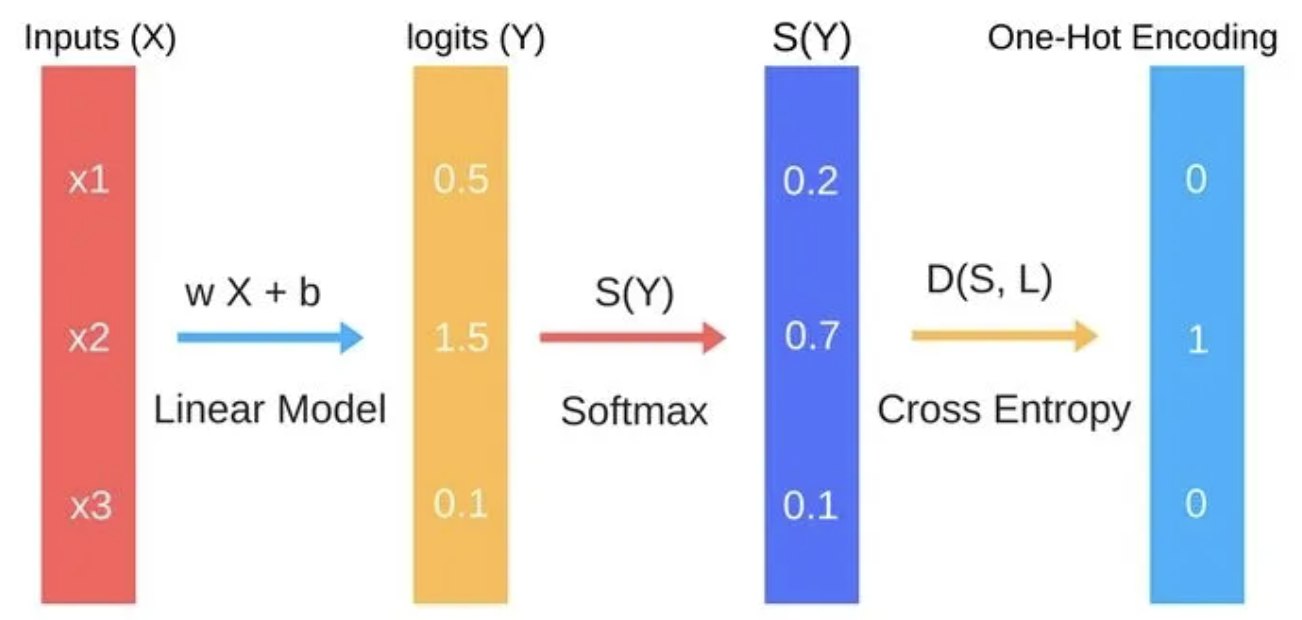
Multiclass logistic regression using softmax function (multinomial)
In the previous example, we created a logistic regression model for multiclass classification using the One-vs-All approach. In the softmax approach, the output of the logistic regression model is a vector of probabilities for each class. The class with the highest probability is then selected as the predicted class.
To use the softmax approach with logistic regression in scikit-learn, we need to set the multi_class parameter to ‘multinomial’ and the solver parameter to a solver that supports the multinomial loss function, such as ‘lbfgs’, ‘newton-cg’, or ‘sag’. Here’s an example of how to create a logistic regression model with multi_class set to ‘multinomial’:
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
model = LogisticRegression(solver='lbfgs', multi_class='multinomial')
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = np.mean(y_pred == y_test)
print("Accuracy:", accuracy)
new_data = np.array([[5.1, 3.5, 1.4, 0.2]])
y_pred = model.predict(new_data)
print("Prediction:", y_pred)In this example, we have set the multi_class parameter to ‘multinomial’ and the solver parameter to ‘lbfgs’. The lbfgs solver is suitable for small datasets like the load_iris dataset. We then train the logistic regression model on the training data and evaluate its performance on the test data.
We can also use the predict_proba method to get the probability estimates for each class for a given input. Here’s an example:
probabilities = model.predict_proba(new_data)
print("Probabilities:", probabilities)
In this example, we have used the predict_proba method to get the probability estimates for each class for the new data point. The output is a vector of probabilities for each class.
It’s important to note that the logistic regression model is a linear model and may not perform well on complex non-linear datasets. In such cases, other algorithms like decision trees, random forests, and support vector machines may perform better.
Conclusion
In conclusion, we have seen how to create a logistic regression model using the scikit-learn library for multiclass classification problems using the OvA and softmax approach. The softmax approach can be more accurate than the One-vs-All approach but can also be more computationally expensive. We have used the load_iris dataset for demonstration purposes but the same steps can be applied to any multiclass classification problem. It’s important to choose the right algorithm based on the characteristics of the dataset and the problem requirements.
Can logistic regression be used for multiclass classification?
Logistic regression is a binary classification model. To support multi-class classification problems, we would need to split the classification problem into multiple steps i.e. classify pairs of classes.
Can you use logistic regression for a classification problem with three classes?
Yes, we can apply logistic regression on 3 class classification problem. Use One Vs rest method for 3 class classification in logistic regression.
When do I use predict_proba() instead of predict()?
The predict() method is used to predict the actual class while predict_proba() method can be used to infer the class probabilities (i.e. the probability that a particular data point falls into the underlying classes). It is usually sufficient to use the predict() method to obtain the class labels directly. However, if you wish to futher fine tune your classification model e.g. threshold tuning, then you would need to use predict_proba()
What is softmax function?
The softmax function is a function that turns a vector of K real values into a vector of K real values that sum to 1. The input values can be positive, negative, zero, or greater than one, but the softmax transforms them into values between 0 and 1, so that they can be interpreted as probabilities. Learn more in this article.
Why and when is Softmax used in logistic regression?
The softmax function is used in classification algorithms where there is a need to obtain probability or probability distribution as the output. Some of these algorithms are the following: Neural networks. Multinomial logistic regression (Softmax regression)
Why use softmax for classification?
Softmax classifiers give you probabilities for each class label. It’s much easier for us as humans to interpret probabilities to infer the class labels.